Most publicly available datasets or datasets at the workplace are complete. However, from time to time we encounter datasets where some or many entries are missing. The problem of missing data exists on a spectrum; only a few entries missing among millions is virtually negligible, however, upwards of 10% of missing data can be crippling.
The exact problem of missing data contains multiple layers, so let us proceed to peel it like the onion it is. At its most basic, enough missing data may skew the distribution(s) the data follows.
In a supervised context, this also skews the distribution of variable-label relationships. In some machine learning models, like simple Linear Regression, the distribution the data is expected to follow is implicitly assumed ( ie. Normal Distribution). In other places, like Bayesian models, the distribution can be explicitly chosen by the Data Scientist. At the end of the day, if we fit/train the data with an inappropriate distribution, it will be very inaccurate with test data. As Data Scientists, we often hope that the test and training data follow very similar if not identical distributions.
(I use the word 'hope' not in the naive sense but to suggest some uncertainty in how our model performs on the test data - an uncertainty all Data Scientists respect.)
In an unsupervised context, say clustering, the skew of distribution will lead to odd clusterings.
This article focuses on the cases in which missing data is too large to be ignored and must be imputed. Imputation of data refers to the process whereby missing data is substituted with very realistic substitutes to maintain the integrity of the distribution of data.
Just like the problem of missing data exists on a spectrum, so do the solutions. If the dataset is simple and the missing is small (say around 5%), one may be able to get away with a simple approach. However, given complicated datasets and larger amounts of missing data, a more involved imputation process is involved.
Identifying Missing Data
Missing data comes in many forms. Mostly the missing data is represented as 'Nan', other times simply as a zero (0) and other times as a special string eg. 'N/A'. Consider this popular IMDB dataset with missing data.
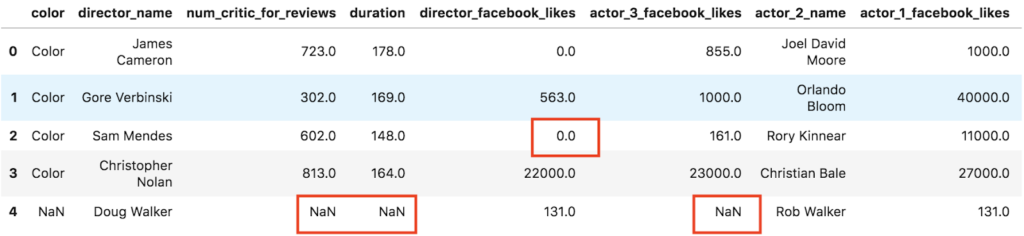
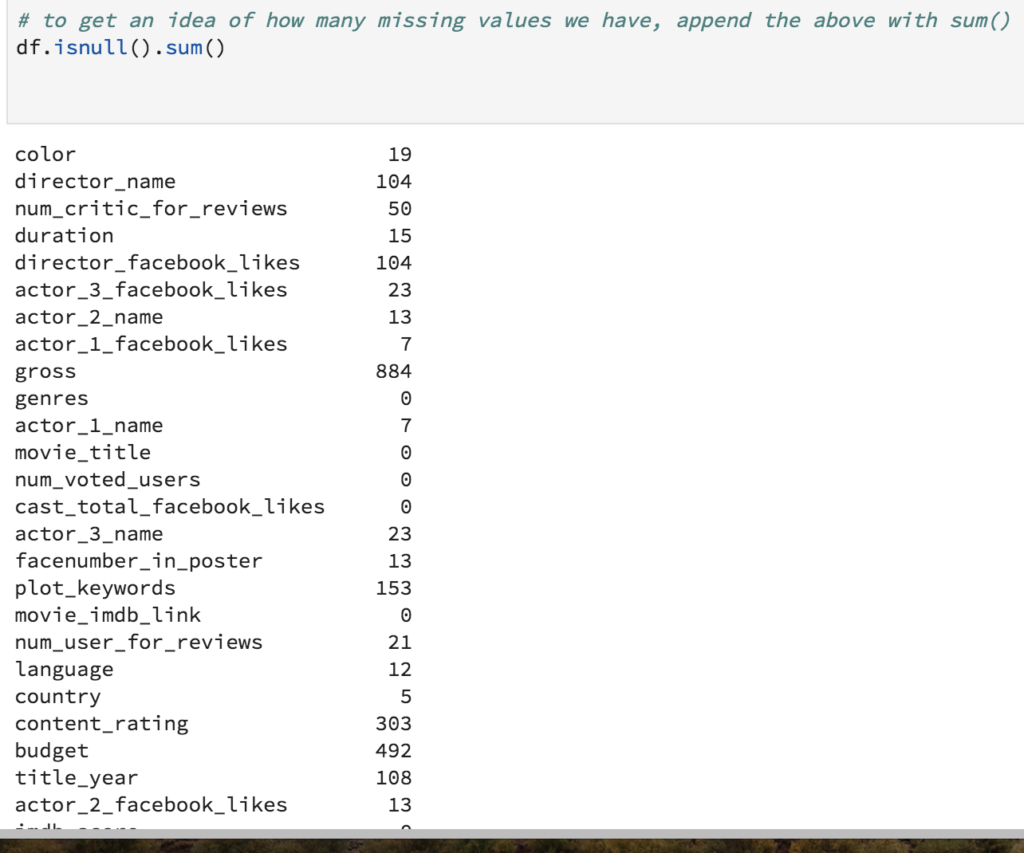
If the missing data is "NaN" we can use the built-in isnull() function in Pandas to understand the count of missing entries.
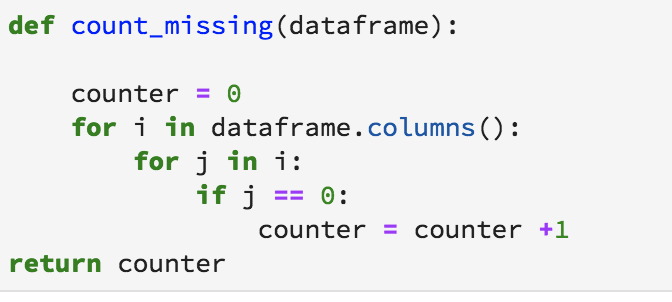
In the case of zeros or non-standard representations, we will have to depend on string matching, perhaps even using Regular Expressions, to get the missing entries count. Here is a naive implementation of counting up all entries of zeros.
After understanding the gravity of the problem, we have two possible solutions depending on the extremity of missing entries.
Simple Approach: Imputation with simple statistics
The simplest approach is to impute the missing entry with the mean/mode of the column the entry belongs to. Here is a simple implementation for the "director_facebook_likes" column.
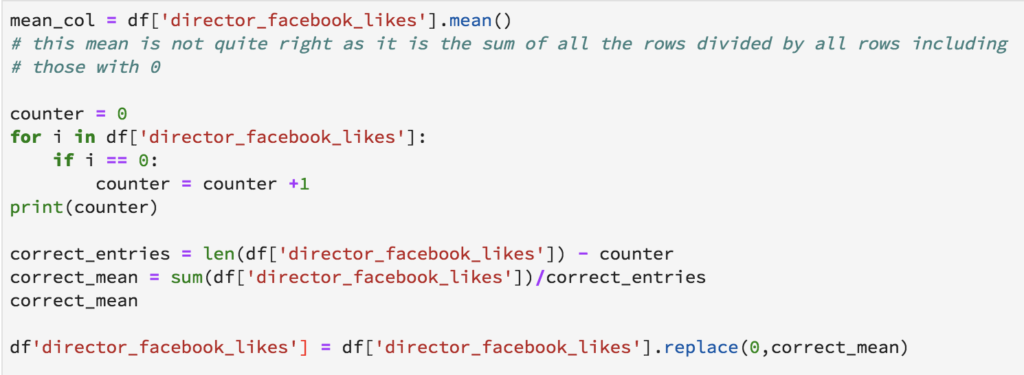
This simple approach may be fair for certain datasets, but for many, the missing entry substitute might be very realistic. To take the example of this dataset, perhaps the number of facebook likes is a function of other variables like Gross, Genre or Rating. Consequently, we will not impute the missing entries by a single number but our imputations will be more specific. Directors whose movies receive ratings of more than 8 may be imputed by a single number, Directors receiving ratings of less than 5 may be imputed by another.
Try imputing the numbers of this column by more realistic entries using other variables.
Predicting missing data
While imputing missing entries with the help of other variables may often be possible, what if we have a dataset with nonsensical column names? What if we are squeezed of time and need a reliable model quick? Sometime it is just not possible to impute missing data with means and modes and we need to treat the missing entries as labels we need to predict.
This process is part supervised, part unsupervised. It is supervised in that we will use the other variables to predict the missing entries, however, we will not be able to understand the goodness of our results immediately. Only once we have completed imputation, fit and run the model on test data will we be able to gauge the accuracy of our missing entry substitutes.
I will use the simple linear regression model to predict the missing entries of "gross". One can experiment with different algorithms and check which gives the best accuracy instead of sticking to a single algorithm.
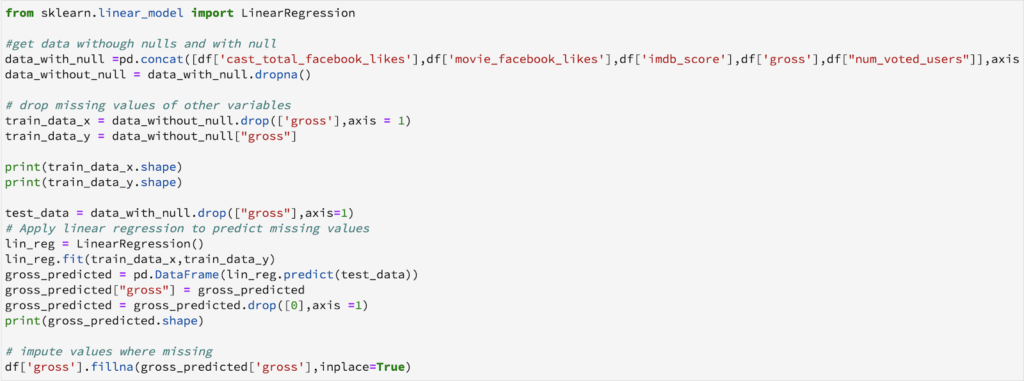
From time to time, we will come across datasets have some missing values which need to be dealt with. But handling them in an intelligent way and giving rise to robust models is a challenging task. We have gone through a number of ways in which nulls can be replaced. It is not necessary to handle a particular dataset in one single manner. One can use various methods on different features depending on how and what the data is about. Having a small domain knowledge about the data is important, which can give you an insight about how to approach the problem.
Now that' you've got this down pat, learn how you can deal with the curse of dimensionality, or check out my article on K-means Clustering for beginners.
Love Data Science? Checkout this intro and immersive data science courses.

